시설 수요 분석
Our Goal
#1. 분석 목표
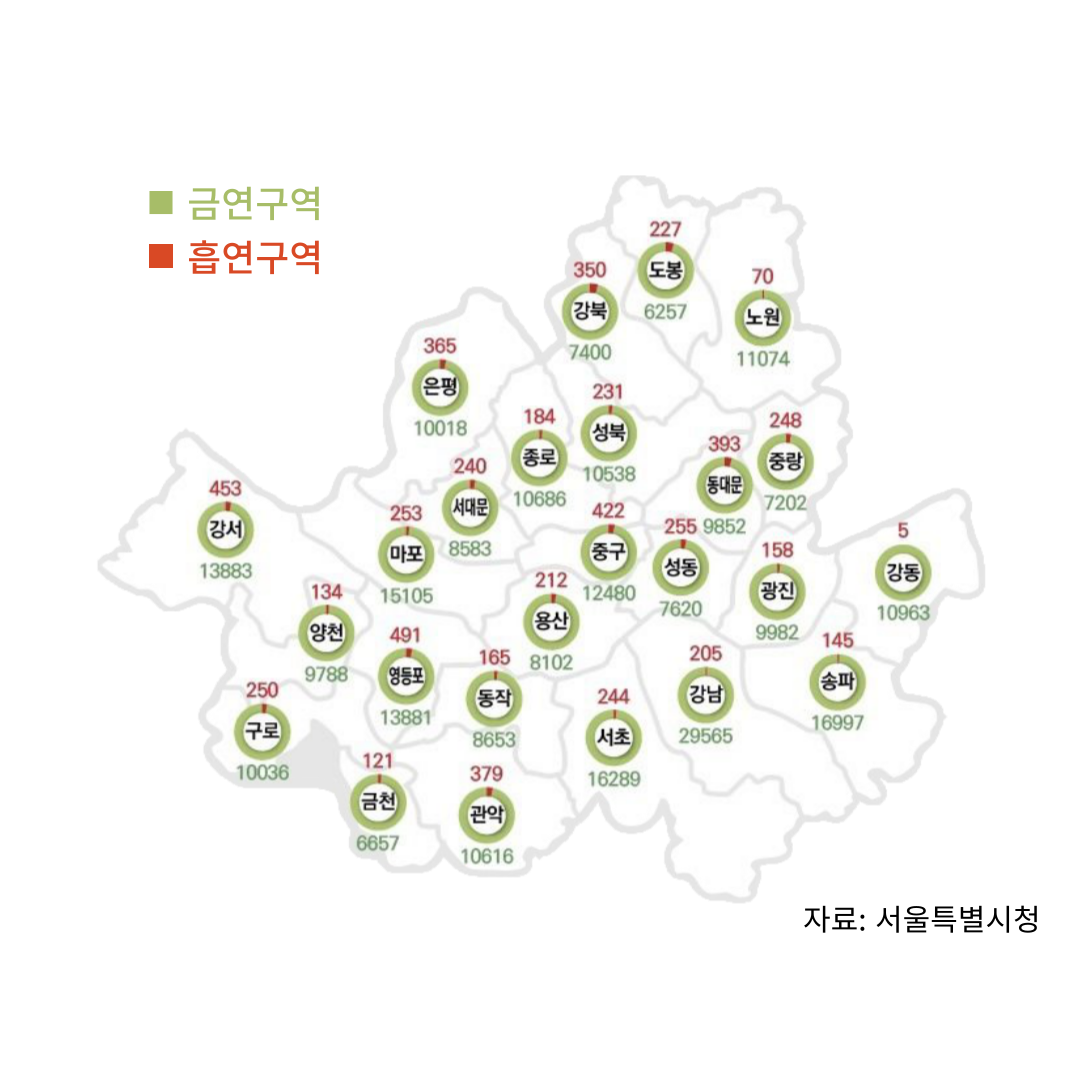
서울 금연∙흡연구역 현황
금연구역(28만 2641개소)
97.6%
흡연구역(6200개소)
2.4%
현재 서울시는 금연구역으로 지정된 장소에 비해 흡연구역은 턱 없이 부족한 상황이다. 대부분의 사람들은 흡연구역의 위치를 정확히 알지 못해 골목길과 같은 곳으로 몰리게 되어 많은 시민들이 불편을 겪게 되고, 특히 자주 방문하지 않는 지역이나 사람들의 통행이 잦은 곳에서 흡연구역을 찾기란 쉬운 일이 아니다.
본 과제는 흡연자와 비흡연자를 모두 배려하고자 선정하였다. 흡연자의 흡연권은 비흡연자의 혐연권보다 우선 시 될 수 없다. 혐연권이 보장된 채로, 혐연권을 침해하지 않는 선에서의 흡연권을 보장받기 위해서는 금연구역이 아닌 곳에서 흡연해야 한다.
이에 따라 본 서비스는 흡연자들의 올바른 흡연생활을 유도하기 위해 흡연구역 위치를 지도를 통해 시각화하며, 선형회귀분석을 통해 예측치와 현재 실정과의 차이를 파악하여 흡연구역의 수가 부족한 지역은 서울시에 추가 설치를 제안하고자 한다.
Reason for Selection
#2. 독립변수 선정
의료기관 & 도서관
생활법령정보에 따르면 국민건강증진법 제9조 4항에 따라 시설의 전체를 금연구역으로 지정한 경우 금연구역을 알리는 표지를 설치해야 하며, 이 경우 흡연자를 위한 흡연실을 설치할 수 있다. 따라서 시설 전체가 금연구역인 의료기관과 지역 도서관에 흡연실을 설치할 수 있으므로 해당 데이터를 독립변수로 선정하였다.
지하철역 & 유흥업소
지하철역은 주로 인구 밀집 지역에 위치하며, 유흥업소 또한 인구 밀집 지역에서 많이 찾아볼 수 있다. 또한, 사람들의 출퇴근과 이동에 사용하는 주요 교통수단은 지하철이다. 인구가 많이 분포한 지역은 흡연시설의 수요도 높을 것이라 판단하여 해당 데이터를 독립변수로 선정하였다.
생활인구 수 & 면적 & 흡연율
‘생활인구’는 해당 지역에서 거주하는 ‘정주인구’와 달리, 지역에서 생활하는 인구를 뜻한다. 지역에 거주하지 않더라도 정기적으로 해당 지역을 방문하거나 일정 기간 생활을 반복하는 인구도 해당 지역의 인구로 보는 개념이다. 이러한 지역마다의 생활인구 수와 이 중 흡연자의 비율이 흡연시설의 수와 상관관계가 있다고 판단하여 해당 데이터를 독립변수로 선정하였다.
visualization
#3. 독립변수 시각화
Permutation Importance
#4. Permutation Importance
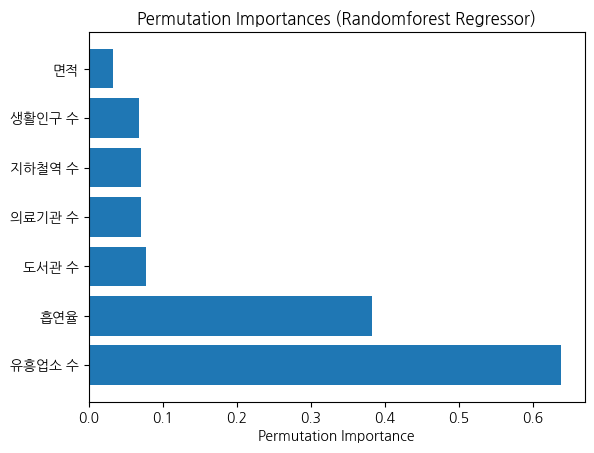
Random Forest 모델에서 Permutation Importance를 사용하여 ‘흡연부스 수’ 종속변수 칼럼에 대한 각 독립변수의 중요도를 판단하였다.
Random Forest Regressor은 변수의 중요도를 내부적으로 트리의 분기마다 고려하므로, 모델이 학습된 후에 변수의 중요도를 평가하는 Permutation Importance의 경우 분기마다 계산할 수 있는 Random Forest 모델을 통해 계산하는 것이 적합하다고 판단하였다.
각 칼럼들의 변수 값을 임의로 섞는 과정을 500번 반복하게 설정한 후, 섞인 변수를 사용하여 성능 변화를 측정하여 변화 값의 크기에 따라 변수 중요도를 계산하였다.
계산 결과, 흡연율과 유흥업소 수가 흡연부스 수 변화에 가장 중요한 변수임을 확인할 수 있었다.
Linear Regression을 이용한
#5. 흡연구역 수요 파악
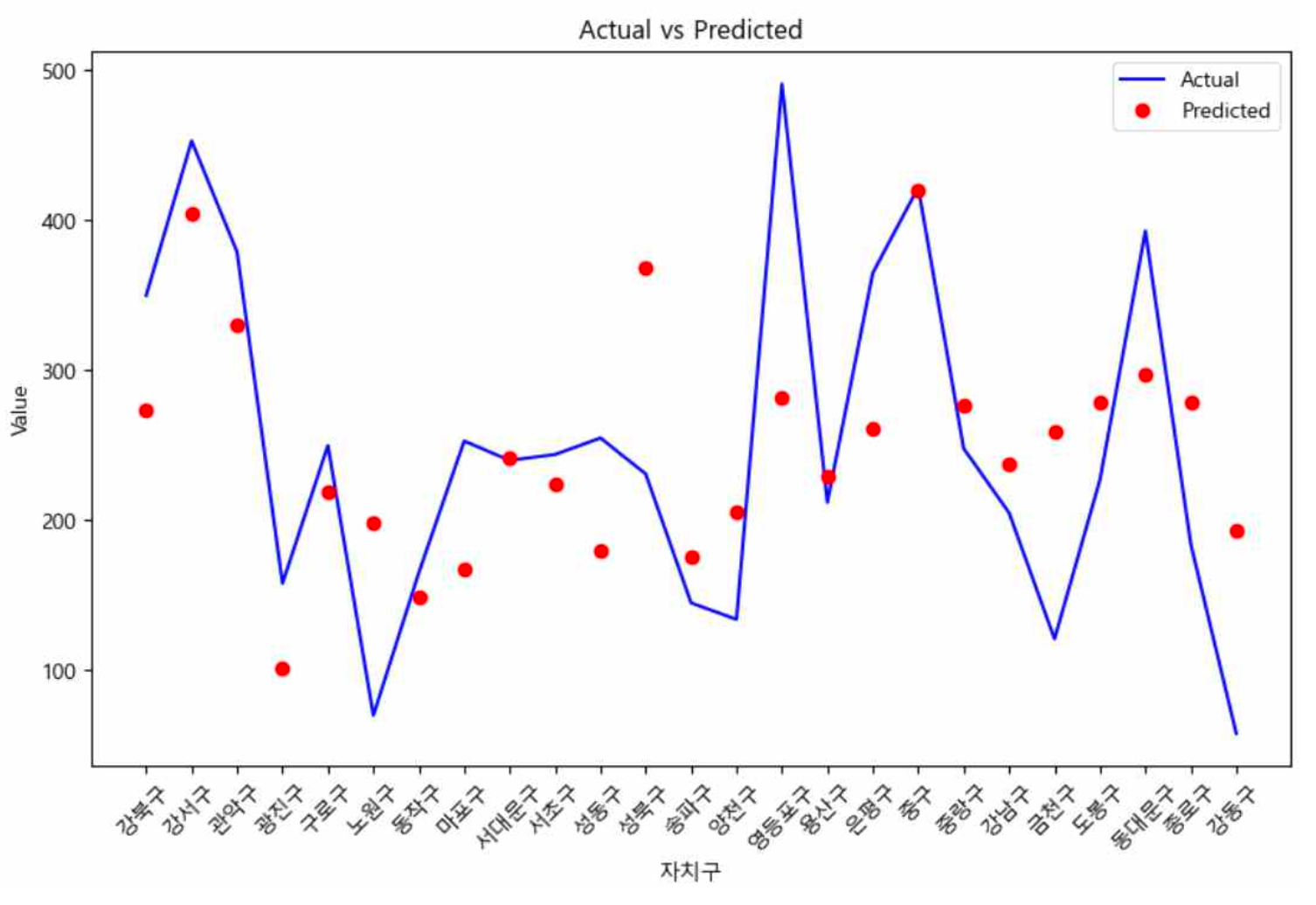
새로운 데이터에 대한 예측을 하는 상황이 아닌, 서울시 내에 있는 자치구에 대해서만 예측하면 되기 때문에 train과 test를 나누지 않고 진행하였다. 선정한 독립변수에 따라 흡연부스 수를 예측하는 선형회귀 모델을 생성하였다. 모델을 학습시킨 후, 선형회귀 모델을 통해 예측한 흡연부스의 수와 실제 흡연부스의 수의 잔차를 통해 흡연부스가 더 필요한 자치구와 이미 충분한 자치구를 파악할 수 있었다.